The control flow graph below is from a single function in Notepad (Win7 64-bit). Why is the linker (or the compiler) separating the basic blocks of a single function into multiple, discontinuous ( not contiguous ) chunks?
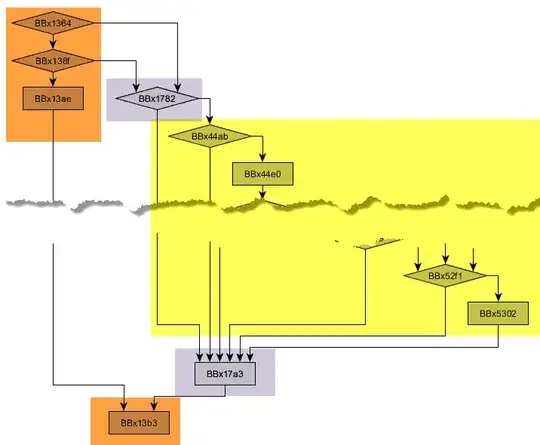
The control flow graph below is from a single function in Notepad (Win7 64-bit). Why is the linker (or the compiler) separating the basic blocks of a single function into multiple, discontinuous ( not contiguous ) chunks?
DCoder already referenced his own answer in a comment.
The chunks in the control flow graph are usually referred to as basic blocks or extended basic blocks. The reason why they are being reordered has to with optimizations performed by the compiler.
There are several terms for what you are asking about:
I strongly suggest that if you are interested in this topic, you read up on compiler design. In particular I would suggest reading "the dragon book" ("Compilers - Principles, Techniques, & Tools" by Aho, Lam, Sethi and Ullman) and there the parts about optimization. Here I refer to the second edition from 2007 (ISBN: 0-321-48681-1).
Check out the sections 8.4 ("Basic Blocks and Flow Graphs") and 8.5 ("Optimization of Basic Blocks") and in the latter 8.5.7 ("Reassembling Basic Blocks From DAGs"). But that's only the beginning. Chapter 9 is equally important as a whole and so is section 11.10 ("Locality Optimizations"). Quoting one of the reasons for the kind of optimization you're asking about from the introductory paragraph of the subsection on partition interleaving:
11.10.3 Partition Interleaving
Different partitions in a loop often read the same data, or read and write the same cache lines. [...]
quoted from "Compilers - Principles, Techniques, & Tools" by Aho, Lam, Sethi and Ullman.
This boils down to what DCoder has already mentioned in his/her comment to your question.
Oh and the book "Reversing: Secrets of Reverse Engineering" is also a good read that discusses this in part. However, it's more focused on the "how does it look" than the "why is it done".