There are 2 similar problems:
Problem I
$$ \arg \min_{x} \frac{1}{2} \left\| A x - b \right\|_{2}^{2} + \lambda \left\| x \right\|_{p} $$
Problem II
$$ \arg \min_{x} \frac{1}{2} \left\| A x - b \right\|_{2}^{2} + \lambda \left\| x \right\|_{p}^{p} $$
Solution Problem I
The function is given by:
$$ f \left( x \right) = \frac{1}{2} \left\| A x - b \right\|_{2}^{2} + \lambda \left\| x \right\|_{p} $$
The derivative is given by:
$$ \frac{d}{d x} f \left( x \right) = {A}^{T} \left( A x - b \right) + \lambda p X x $$
Where the matrix $ X $ is a diagonal matrix given by:
$$ {X}_{ii} = \left| {x}_{i} \right|^{p - 2} \frac{\left\| x \right\|_{p}^{ \frac{1}{p} - 1 }}{p} $$
The derivative vanishes at:
$$ x = \left( {A}^{T} A + \lambda p X \right)^{-1} {A}^{T} b $$
Since $ X $ dpends on $ x $ the method to solve it is using the Iterative Reweighted Least Squares (IRLS):
$$ {x}^{k + 1} = \left( {A}^{T} A + \lambda p {X}^{k} \right)^{-1} {A}^{T} b $$
The Code:
%% Solution by Iterative Reweighted Least Squares (IRLS) - Problem I
hObjFun = @(vX) (0.5 * sum((mA * vX - vB) .^ 2)) + (paramLambda * norm(vX, paramP));
vObjVal = zeros([numIterations, 1]);
mAA = mA.' * mA;
vAb = mA.' * vB;
vX = mA \ vB; %<! Initialization by the Least Squares Solution
vObjVal(1) = hObjFun(vX);
for ii = 2:numIterations
mX = diag((sum(abs(vX) .^ paramP) .^ ((1 / paramP) - 1)) .* abs(vX) .^ (paramP - 2));
vX = (mAA + (paramLambda * mX)) \ vAb;
vObjVal(ii) = hObjFun(vX);
end
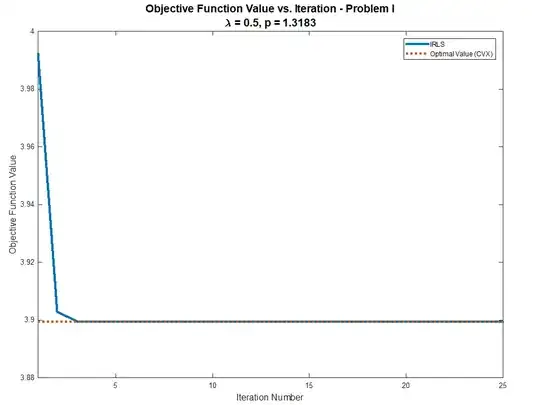
Solution Problem II
The function is given by:
$$ f \left( x \right) = \frac{1}{2} \left\| A x - b \right\|_{2}^{2} + \lambda \left\| x \right\|_{p}^{p} $$
The derivative is given by:
$$ \frac{d}{d x} f \left( x \right) = {A}^{T} \left( A x - b \right) + \lambda p X x $$
Where the matrix $ X $ is a diagonal matrix given by:
$$ {X}_{ii} = \left| {x}_{i} \right|^{p - 2} $$
The derivative vanishes at:
$$ x = \left( {A}^{T} A + \lambda p X \right)^{-1} {A}^{T} b $$
Since $ X $ dpends on $ x $ the method to solve it is using the Iterative Reweighted Least Squares (IRLS):
$$ {x}^{k + 1} = \left( {A}^{T} A + \lambda p {X}^{k} \right)^{-1} {A}^{T} b $$
Where:
$$ {X}_{ii}^{k} = \left| {x}_{i}^{k} \right|^{p - 2} $$
The Code is given by:
%% Solution by Iterative Reweighted Least Squares (IRLS)
hObjFun = @(vX) (0.5 * sum((mA * vX - vB) .^ 2)) + (paramLambda * sum(abs(vX) .^ paramP));
vObjVal = zeros([numIterations, 1]);
mAA = mA.' * mA;
vAb = mA.' * vB;
vX = mA \ vB; %<! Initialization by the Least Squares Solution
vObjVal(1) = hObjFun(vX);
for ii = 2:numIterations
mX = diag(abs(vX) .^ (paramP - 2));
vX = (mAA + (paramLambda * paramP * mX)) \ vAb;
vObjVal(ii) = hObjFun(vX);
end
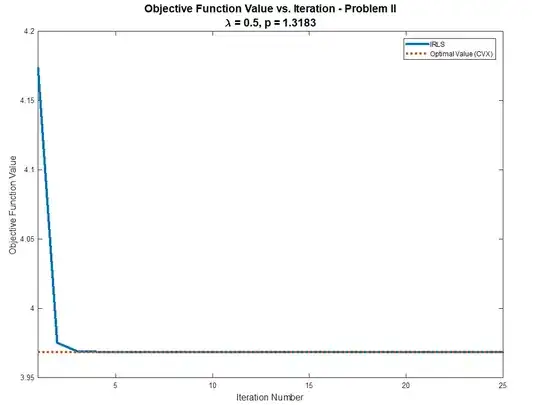
The code is available (Including validation by CVX) at my StackExchange Mathematics Q2403596 GitHub Repository.

