I recently did a homework where I had to learn a model for the MNIST 10-digit classification. The HW had some scaffolding code and I was supposed to work in the context of this code.
My homework works / passes tests but now I'm trying to do it all from scratch (my own nn framework, no hw scaffolding code) and I'm stuck applying the grandient of softmax in the backprop step, and even think what the hw scaffolding code does might not be correct.
The hw has me use what they call 'a softmax loss' as the last node in the nn. Which means, for some reason they decided to join a softmax activation with the cross entropy loss all in one, instead of treating softmax as an activation function and cross entropy as a separate loss function.
The hw loss func then looks like this (minimally edited by me):
class SoftmaxLoss:
"""
A batched softmax loss, used for classification problems.
input[0] (the prediction) = np.array of dims batch_size x 10
input[1] (the truth) = np.array of dims batch_size x 10
"""
@staticmethod
def softmax(input):
exp = np.exp(input - np.max(input, axis=1, keepdims=True))
return exp / np.sum(exp, axis=1, keepdims=True)
@staticmethod
def forward(inputs):
softmax = SoftmaxLoss.softmax(inputs[0])
labels = inputs[1]
return np.mean(-np.sum(labels * np.log(softmax), axis=1))
@staticmethod
def backward(inputs, gradient):
softmax = SoftmaxLoss.softmax(inputs[0])
return [
gradient * (softmax - inputs[1]) / inputs[0].shape[0],
gradient * (-np.log(softmax)) / inputs[0].shape[0]
]
As you can see, on forward it does softmax(x) and then cross entropy loss.
But on backprop, it seems to only do the derivative of cross entropy and not of softmax. Softmax is left as such.
Shouldn't it also take the derivative of softmax with respect to the input to softmax?
Assuming that it should take the derivative of softmax, I'm not sure how this hw actually passes the tests...
Now, in my own implementation from scratch, I made softmax and cross entropy separate nodes, like so (p and t stand for predicted and truth):
class SoftMax(NetNode):
def __init__(self, x):
ex = np.exp(x.data - np.max(x.data, axis=1, keepdims=True))
super().__init__(ex / np.sum(ex, axis=1, keepdims=True), x)
def _back(self, x):
g = self.data * (np.eye(self.data.shape[0]) - self.data)
x.g += self.g * g
super()._back()
class LCE(NetNode):
def __init__(self, p, t):
super().__init__(
np.mean(-np.sum(t.data * np.log(p.data), axis=1)),
p, t
)
def _back(self, p, t):
p.g += self.g * (p.data - t.data) / t.data.shape[0]
t.g += self.g * -np.log(p.data) / t.data.shape[0]
super()._back()
As you can see, my cross entropy loss (LCE) has the same derivative as the one in the hw, because that is the derivative for the loss itself, without getting into the softmax yet.
But then, I would still have to do the derivative of softmax to chain it with the derivative of loss. This is where I get stuck.
For softmax defined as:
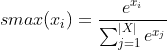
The derivative is usually defined as:
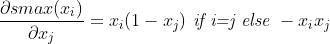
But I need a derivative that results in a tensor of the same size as the input to softmax, in this case, batch_size x 10. So I'm not sure how the above should be applied to only 10 components, since it implies that I would diferentiate for all inputs with respect to all outputs (all combinations) or 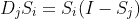 in matrix form.
in matrix form.
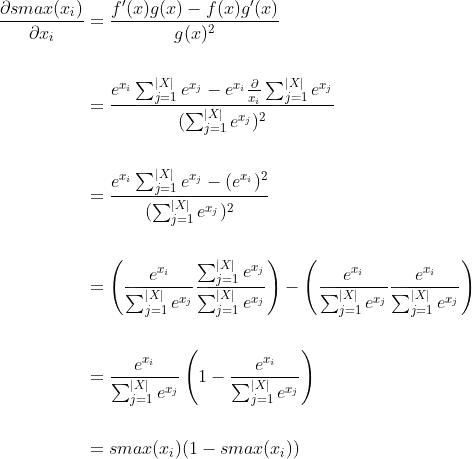
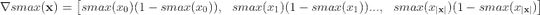
the implementation of machine learning"
– mico Mar 30 '18 at 09:39