Overview
Let's say I have the following data:
# Label\Target VM
#2000-01-01 00:00:00 App3 VM9
#2000-01-01 01:00:00 App3 VM3
#2000-01-01 02:00:00 App1 VM1
#2000-01-01 03:00:00 App1 VM8
#2000-01-01 04:00:00 -> None VM1
#... ... ...
#2000-12-31 19:00:00 -> None VM5
#2000-12-31 20:00:00 App3 VM1
#2000-12-31 21:00:00 App3 VM7
#2000-12-31 22:00:00 App1 VM3
#2000-12-31 23:00:00 App2 VM8
I have 3 classes (App1, App2, App3) + None.
Nonerepresents missing values inLabel\Targetcolumn.
Problem definition
Problem: is to classify\predict missing values represented by None in Label\Target column given a time series.
None ==?==> (App1, App2, App3)?
I'm unsure which approach to take with partially labeled data.
- Approach1: consider 3 classes
(App1, App2, App3) - Approach2: consider 4 classes
(App1, App2, App3)+None
Which method should I use?
The thing that crossed my mind is Self-Supervised Learning (SSL)

What about Self-Supervised Learning?
I did some research to see the best practice to approach this problem and what is State-of-the-art. I found this article:
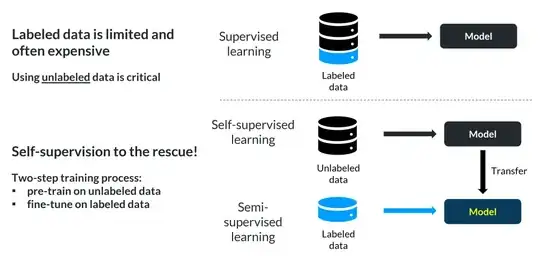
How about Semi-Supervised Learning?
"Semi-supervised learning is particularly useful when there is a large amount of unlabeled data available, but it’s too expensive or difficult to label all of it." Ref

But still, I'm confused and even unsure if this problem is classify\predict or forecast missing label.
Reproducible data generation
Following is sampled data if you had a Pythonic solution:
import numpy as np
import pandas as pd
import random
np.random.seed(2023)
Generate TS
ts = pd.date_range('2000-01-01', '2000-12-31 23:00', freq='H')
number of samples
N = len(ts)
Create a random dataset
data = {
#"TS": ts,
'Appx': [random.choice(['App1', 'App2', 'App3', None]) for _ in range(N)],
'VM': [random.choice(['VM1' , 'VM2' , 'VM3', 'VM4', 'VM5', 'VM6']) for _ in range(N)]
}
df = pd.DataFrame(data, index=ts)
df
Question
I need best practice to frame the problem correctly for this scenario to predict missing labels in partially labeled data over time and possible approaches (Approach1 or 2) based on state-of-the-art and recent methods (Semi\Self-supervised learning). I have generated sample data if someone wants to offer the minimal solution(s).
Any help will be highly appreciated.
(App1, App2, App3), or we need to consider 4 classes(App1, App2, App3)+None? – Mario Oct 10 '23 at 23:18[MASK]to be consistent with BERT, but you can call itNone. – noe Oct 10 '23 at 23:30