Does this reflect the real world and what is the empirical evidence behind this?

Layman here so please avoid abstract math in your response.
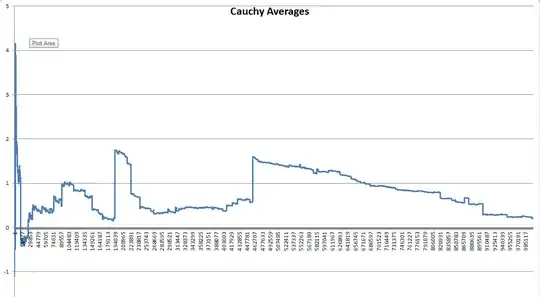
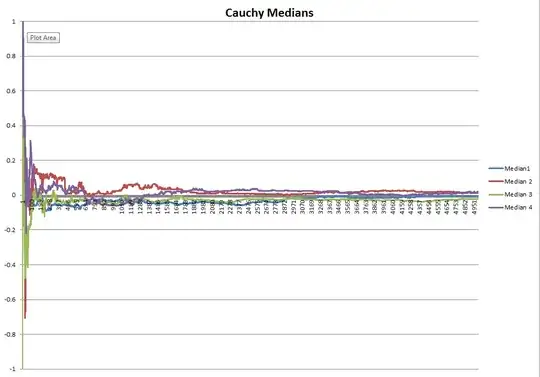
The Law of Large Numbers states that the average of the results from multiple trials will tend to converge to its expected value (e.g. 0.5 in a coin toss experiment) as the sample size increases. The way I understand it, while the first 10 coin tosses may result in an average closer to 0 or 1 rather than 0.5, after 1000 tosses a statistician would expect the average to be very close to 0.5 and definitely 0.5 with an infinite number of trials.
Given that a coin has no memory and each coin toss is independent, what physical laws would determine that the average of all trials will eventually reach 0.5. More specifically, why does a statistician believe that a random event with 2 possible outcomes will have a close to equal amount of both outcomes over say 10,000 trials? What prevents the coin to fall 9900 times on heads instead of 5200?
Finally, since gambling and insurance institutions rely on such expectations, are there any experiments that have conclusively shown the validity of the LLN in the real world?
EDIT: I do differentiate between the LLN and the Gambler's fallacy. My question is NOT if or why any specific outcome or series of outcomes become more likely with more trials--that's obviously false--but why the mean of all outcomes tends toward the expected value?
FURTHER EDIT: LLN seems to rely on two assumptions in order to work:
- The universe is indifferent towards the result of any one trial, because each outcome is equally likely
- The universe is NOT indifferent towards any one particular outcome coming up too frequently and dominating the rest.
Obviously, we as humans would label 50/50 or a similar distribution of a coin toss experiment "random", but if heads or tails turns out to be say 60-70% after thousands of trials, we would suspect there is something wrong with the coin and it isn't fair. Thus, if the universe is truly indifferent towards the average of large samples, there is no way we can have true randomness and consistent predictions--there will always be a suspicion of bias unless the total distribution is not somehow kept in check by something that preserves the relative frequencies.
Why is the universe NOT indifferent towards big samples of coin tosses? What is the objective reason for this phenomenon?
NOTE: A good explanation would not be circular: justifying probability with probabilistic assumptions (e.g. "it's just more likely"). Please check your answers, as most of them fall into this trap.
{kind=link}
Each path through the board has an equal probability. But a lot more of the paths end in the centre than at the edge!
– Ben Aaronson Jan 30 '15 at 15:06